
Executive Hook: Memory, Not Model Size, Decides Who Wins With AI
We’ve hit a turning point. The companies extracting meaningful value from large language models aren’t just picking better models; they’re engineering better memory. In practical terms, that means deliberately deciding what the AI should remember, for how long, and under what guardrails-turning raw capability into repeatable advantage. If you’re still chasing the biggest model and the longest context window, you’re playing last year’s game.
Why this matters now: most enterprise-friendly LLMs operate within 4,000-32,000 tokens of “working memory.” That’s generous for a single task, but not enough to carry a relationship, a workflow, or a product across time. The winners are building memory stacks that keep interactions coherent, compliant, and cost-effective across sessions.
Industry Context: The Competitive Edge Is Shifting to Memory Architecture
Across sectors-from game publishers running live ops to banks managing complex customer journeys-leaders want AI that remembers. Not just the last prompt, but the player’s history, the policy constraints, the relevant knowledge, and the decisions already made. Memory is what prevents repetition, enables personalization, and tames cost by avoiding reprocessing the same information.
Vendors are racing to respond. Microsoft has leaned into long-term memory research and tooling (think retrieval patterns like GraphRAG, Azure AI orchestration, and Semantic Kernel’s pluggable memory), while model labs showcase ever-longer context windows. Those longer windows are useful, but they’re not a strategy. The durable moat is how you capture, structure, retrieve, and govern your organization’s knowledge and interaction history—safely and cheaply.
Core Insight: Compete on Memory Design, Not Just Model Choice
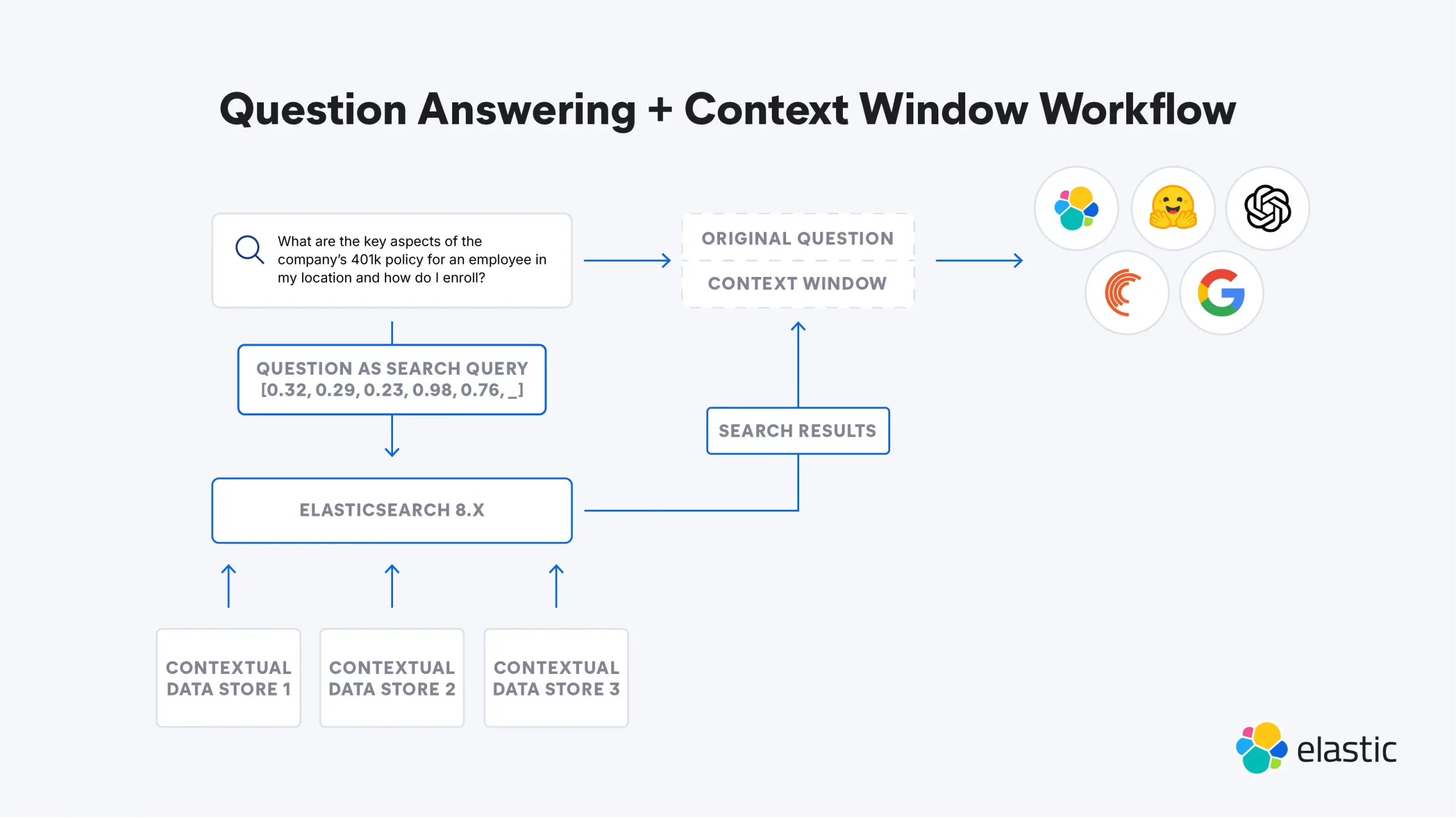
LLM “memory” isn’t monolithic. Treat it as a layered system:
- Working memory: the context window—the model’s short-term recall per request or conversation.
- Semantic memory: your stable knowledge (docs, wikis, code, policies) reachable via retrieval-augmented generation (RAG) and indexing.
- Episodic memory: the history of interactions and decisions tied to a user, case, or session.
- Identity/profile memory: preferences, permissions, and roles that shape behavior.
- Policy/guardrail memory: rules that constrain actions (compliance, safety, tone) enforced consistently.
The breakthrough we see in successful programs isn’t a bigger context—it’s a deliberate split: keep the context window lean, and push everything else into well-governed external memory with smart retrieval. That delivers better quality, lower latency, and a cleaner compliance story.
Common Misconceptions (And What To Do Instead)
- Misconception: “We’ll just buy the largest context window.” Reality: costs and latency climb fast, and relevance drops near the window edge. Better: index content, retrieve selectively, and summarize to fit within 4k-32k tokens.
- Misconception: “Fine-tuning equals memory.” Reality: fine-tuning adjusts behavior; it doesn’t store dynamic facts or user histories. Better: use fine-tuning for style/policy; use RAG and profiles for knowledge/personalization.
- Misconception: “RAG alone solves memory.” Reality: generic RAG misses relationships and recency without careful chunking, metadata, and graph or event models. Better: combine vector search with structured schemas (entities, timelines) and caching.
- Misconception: “The model learns from each chat.” Reality: stateless by default; nothing persists unless you design it. Better: implement explicit episodic memory with consent and retention controls.
- Misconception: “Store everything—more context means better answers.” Reality: noisy memory harms accuracy and raises risk. Better: curate, expire, and compress; measure utility before you persist.
- Misconception: “Privacy is an add-on.” Reality: memory creates data liability. Better: data minimization, encryption, role-based retrieval, audit trails, and region-aware storage by default.
Strategic Framework: The M.E.M.O.R.Y. Playbook
- M — Map use cases by memory need. Classify tasks by conversational depth, cross-session continuity, and knowledge breadth. Decide where you need working memory (context), episodic memory (history), semantic memory (knowledge), or all three.
- E — Engineer a layered stack. Pair a right-sized model with retrieval (vector + metadata), profile stores, and policy enforcement. Use summaries and references, not raw dumps, inside the prompt.
- M — Minimize cost and latency. Chunk documents well, pre-index with quality signals, cache frequent answers, and precompute summaries. Keep token budgets tight.
- O — Orchestrate governance. Define who can write/read memory, data retention windows, PII handling, redaction, and auditability. Treat memory like a product with SLAs and risk controls.
- R — Reinforce with feedback loops. Instrument outcomes (helpfulness, hallucination rate, escalation rate), run evaluations with golden sets, and use human review to improve retrieval and prompts.
- Y — Yield measurable outcomes. Tie memory to business KPIs: CSAT, first-contact resolution, handle time, conversion, developer velocity, and infrastructure spend per successful task.
Action Steps: What To Do Monday Morning
- Identify three workflows where memory would change outcomes (e.g., multi-session support, compliance-heavy authoring, complex onboarding).
- Write a one-page “memory contract” for each: what to remember, how long, who can access, and how to delete.
- Pick a model with a practical context window (not just the largest) and instrument token usage from day one.
- Stand up a retrieval layer: vector search plus metadata filtering; seed it with policies, FAQs, and the top 100 tasks.
- Add episodic memory: store concise, signed summaries of each session tied to a user or case ID.
- Establish guardrails: PII redaction, role-based access, encryption at rest and in transit, and auditable logs.
- Pilot with 50-100 real users; measure CSAT, deflection, latency, and cost per resolved task. Iterate weekly.
- Create a retirement plan: how memory expires, when it’s re-summarized, and who approves schema changes.
- Align with IT and Legal on data residency and vendor terms; prefer providers that support private networks and key management (e.g., Azure-hosted options for tight enterprise control).
- Publish a living “memory map” dashboard so product, ops, and compliance see what’s stored and why.
Closing Perspective: Make Memory Your Differentiator
Bigger models will keep arriving. That’s not your moat. Your moat is a memory architecture that’s purposeful, explainable, and economical—one that turns every interaction into compound knowledge without turning your data estate into risk. Design for memory now, and you won’t just deploy LLMs. You’ll scale them responsibly, and profitably.


